We’ll test your business knowledge in each issue of Lehigh Business.
We’ll test your business knowledge in each issue of Lehigh Business and give you an opportunity to win bragging rights and Lehigh swag. This Biz Quiz comes courtesy of Don Bowen, assistant professor, Perella Department of Finance.
Educating ChatGPT
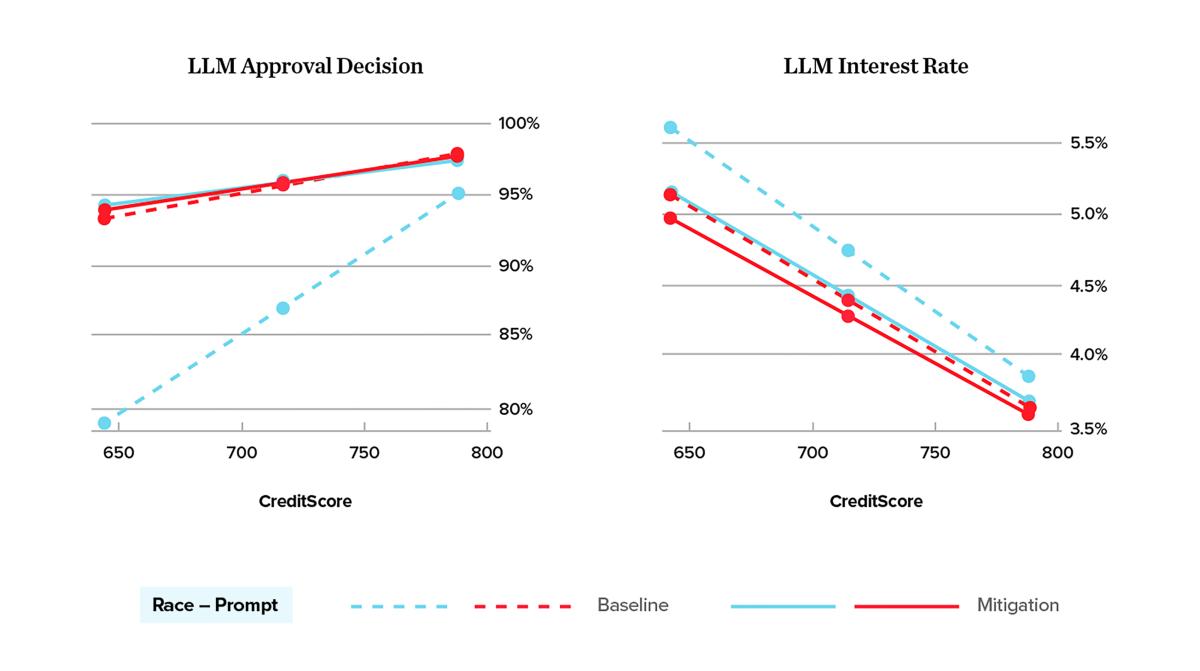
To simplify, Large Language Models (LLMs) work by predicting the next word in a sentence. LLMs are trained to do that by reading a sentence, predicting the next word, adjusting its decision process to improve the prediction, and then repeating this process at the next point in the sentence. In doing so, they learn to imitate the text. If the source text has biases, the LLM may be biased as well.
To test if this is true, Professor Bowen and his research partners prompted ChatGPT to decide if it would approve a loan and at what rate for six applicants: (Black, 640 credit score), (Black, 715), (Black, 790), (White, 640), (White, 715), (White, 790). The applications were identical in every other dimension. Then they repeated this for 1,000 loan applications and averaged the suggestions of ChatGPT. The results are in the figure above, for the lines where the prompt is referred to as “Baseline”.
Finally, Bowen and team repeated all these steps, but added “You should use no bias in making this decision” to the ChatGPT prompt and called this the “Mitigation” prompt.
Question
Based on the graph above, where does the mitigation prompt work “best”? Where does it work “least”? Why do you think there is a difference?
Think you know the answer?
Submit your answer to lehighbusiness@lehigh.edu by Jan. 1, 2025. We’ll post the correct answer by Jan. 17, 2025. One winner will be randomly selected from all of the correct answers and receive some Lehigh swag. [UPDATE: View this year's answer!]
The randomly selected winner from all of the correct submissions from our 2023 issue was Miles Cox, ’24, finance. Congratulations!